Data Mining 101: Finding Subversives with Amazon Wishlists
This series of articles is about replacing corporate software and services that are invasive and coercive with Free community-built alternatives. It focuses on moving from macOS and iOS to Linux and de-Googled Android and finding self-hosted alternatvies to cloud services.
When this article was first published in 2006, it was reported on by the New York Times, BBC News, and Wall Street Journal. It was also covered in Eben Moglen's Computers, Privacy, & the Constitution class at Columbia and in the Washburn Law Journal.
To a modern reader, everything here just seems to obvious.
Vast deposits of personal information sit in databases across the internet. Terms used in phone conversations have become the grounds for federal investigation. Reputable organizations like the Catholic Worker, Greenpeace, and the Vegan Community Project, have come under scrutiny by FBI "counterterrorism" agents.
"Data mining" of all that information and communication is at the heart of the furor over the recent disclosure of government snooping. "U.S. President George W. Bush and his aides have said his executive order allowing eavesdropping without warrants was limited to monitoring international phone and e-mail communications linked to people with connections to al-Qaeda. What has not been acknowledged, according to the Times, is that NSA technicians combed large amounts of phone and Internet traffic seeking patterns pointing to terrorism suspects.
"Some officials described the program as a large data mining operation, the Times said, and described it as much larger than the White House has acknowledged." (Reuters)
Combining a data mining operation with the Patriot Act's power to access information makes it all too easy for the federal government to violate the Constitution's prohibition against unreasonable search. Ars Technica has an article, The new technology at the root of the NSA wiretap scandal, that describes the ease with which widespread wiretapping can now be implemented. It quotes Philip Zimmermann, the creator of the PGP encryption software:
"A year after the CALEA [Communications Assistance for Law Enforcement Act] passed [in 1994], the FBI disclosed plans to require the phone companies to build into their infrastructure the capacity to simultaneously wiretap 1 percent of all phone calls in all major U.S. cities. This would represent more than a thousandfold increase over previous levels in the number of phones that could be wiretapped. In previous years, there were only about a thousand court-ordered wiretaps in the United States per year, at the federal, state, and local levels combined. It's hard to see how the government could even employ enough judges to sign enough wiretap orders to wiretap 1 percent of all our phone calls, much less hire enough federal agents to sit and listen to all that traffic in real time. The only plausible way of processing that amount of traffic is a massive Orwellian application of automated voice recognition technology to sift through it all, searching for interesting keywords or searching for a particular speaker's voice. If the government doesn't find the target in the first 1 percent sample, the wiretaps can be shifted over to a different 1 percent until the target is found, or until everyone's phone line has been checked for subversive traffic. The FBI said they need this capacity to plan for the future. This plan sparked such outrage that it was defeated in Congress. But the mere fact that the FBI even asked for these broad powers is revealing of their agenda."
It used to be you had to get a warrant to monitor a person or a group of people. Today, it is increasingly easy to monitor ideas. And then track them back to people. Most of us don't have access to the databases, software, or computing power of the NSA, FBI, and other government agencies. But an individual with access to the internet can still develop a fairly sophisticated profile of hundreds of thousands of U.S. citizens using free and publicly available resources. Here's an example.
There are many websites and databases that could be used for this project, but few things tell you as much about a person as the books he chooses to read. Isn't that why the Patriot Act specifically requires libraries to release information on who's reading what? For this reason, I chose to focus on the information contained in the popular Amazon wishlists.
Amazon wishlists lets anyone bookmark books for later purchase. By default these lists are public and available to anybody who searches by name. If the wishlist creator specifies a shipping address, someone else can even purchase the book on Amazon and have it shipped directly as a gift. The wishlist creator's city and state are made public on the wishlist, but the street address remains private. Amazon's popularity has created a vast database of wishlists. No index of all wishlists is available, but it remains possible to view all wishlists by people of a particular first name. A recent search for people named Mark returned 124,887 publicly viewable wishlists.
For an all inclusive search by name, you could compile a comprehensive list of first names and nicknames from the baby names databases available on the internet. Armed with this list, and by recording the search results for each first name, it is possible for you to retrieve the vast majority of public wishlists on Amazon.
For the purposes of this exercise, only a single name was chosen – a common male name that returned over 260,000 wishlists. I'm not going to divulge what name was actually used. Let's pretend it was "Edgar," in honor of former FBI director J. Edgar Hoover.
Before writing a script to download all the 260,000 "Edgar" wishlists, I confirmed that my actions would not violate Amazon's Conditions of Use. I also checked the robots.txt file which contains a list of directories Amazon requests not be traversed by scripts. User wishlists are not in this list, nor did the actions to be taken violate the conditions of use.
I started by doing a wishlist search for people named "Edgar" and got back a page linking to the wishlists of the first 25 matches. The url looked something like this:
http://www.amazon.com/gp/registry/search.html/?encoding=UTF8&type=wishlist&field-name=edgar&page=1
Two variables extracted from the above url are of particular note:
- field-name=edgar
- page=1
Changing "edgar" to "george", would generate the first page of matches for people named George. Change '1' to '2' and you'd get matches 26 through 50 instead of 1 through 25.
Using a simple 6-line shell script and the popular wget command line tool, I configured two computers on two different DSL connections to begin downloading all 260,000 wishlists in increments of 25,000. Each group of 25,000 wishlists took about four hours to download, for a total download time of less than one day. Each wishlist is located at an address like this:
http://www.amazon.com/gp/registry/registry.html/?encoding=UTF8&type=wishlist&id=1DBHU3OCV72ZW
1DBHU3OCV72ZW is the wishlist owner's unique Amazon identification number. I made up the one you see here. By directing wget only to download pages at urls similar to this one, and by incrementing the search page from 1 to 10,400, it is possible to download all 260,000 wishlists without user intervention. Using a pair of 5-year-old computers, two home DSL connections, 42 hours of computer time, and 5 man hours, I now had documents describing the reading preferences of 260,000 U.S. citizens.
I downloaded all the files to an external 120 GB Firewire drive in UFS format. The raw data occupied little more than 5 GB. I initially wanted to move all the files into a single directory to facilitate searching, but as the directory contents exceeded 100,000 items, the speed became glacially slow, so I kept the data divided into chunks of 25,000 wishlists.
Next comes the fun part – what books are most dangerous? So many to choose from. Here's a sample of the list I made. Feel free to make up your own list if you decide to try some data mining. Send it to the FBI. I'm sure they'll appreciate your help in fighting terrorism.
- On Liberty by Stuart Mill. First sentence: "The subject of this essay is not the so-called 'liberty of the will', so unfortunately opposed to the misnamed doctrine of philosophical necessity; but civil, or social liberty: the nature and limits of the power which can be legitimately exercised by society over the individual." What more do you need?
- Slaughterhouse-Five by Kurt Vonnegut. The classic anti-war novel.
- Fahrenheit 451 by Ray Bradbury. Dystopian.
- Brave New World by Aldous Huxley. More dystopian.
- 1984 by George Orwell. Most dystopian.
- Critical Thinking by Alec Fisher. Can't have any of that.
- Build Your Own Laser, Phaser, Ion Ray Gun and Other Working Space Age Projects by Robert Iannini. Obviously.
- Apple I Replica Creation by Tom Owad. Building your own computer should be illegal. (ok, it's also here because I wrote it.)
- The Catholic Worker Movement: Intellectual And Spiritual Origins by Mark & Louise Zwick.
Keywords
- Michael Moore. The fringe left.
- Rush Limbaugh. The fringe right.
- Ralph Nader.
- Greenpeace. Because frankly, we all know there's only one sort of person who would want a "Greenpeace: Standing Up for the Earth" 2006 Calendar.
- Torah.
- Quran & Koran. Like the Catholic Worker and Greenpeace, the American-Arab Anti-Discrimination Committee has also been the subject of FBI investigations.
- Bible. Sure, a lot of books use "Bible" in the title, but I cast a wide net. What harm are a few false positives?
My Amazon seller ID is attached to these links. If I get any interesting statistics on how many copies of On Liberty, etc., are sold as a result of this article, I'll post them in a follow-up. If I get a call from the FBI, I'll let you know that, too.
To search for specific books, I used ISBN numbers, for the rest, keywords. All the search terms were saved to terms.txt, one term per line, for use with grep:
ls -1 | xargs grep -HiFof /Volumes/UFS/terms.txt > /Volumes/UFS/matches.txt
This command searches all wishlists in the current directory for the terms in terms.txt, then saves the results to matches.txt. Results are stored one per line, in the format:
filename:keyword
Now that I have a list of which keywords appear in which wishlists, I can sort them. I created a new folder "results" and within it created subfolders for each search term. The TCL script below creates links (similar to aliases or shortcuts) for each matched file, and stores the links within the new subdirectories:
#!/usr/bin/tclsh
set fdgrep [open "/Volumes/UFS/matches.txt" "r"]
while {![eof $fdgrep]} {
gets $fdgrep line
set mylist [split $line :]
if {[llength $mylist] > 1} {
lappend mylist [string toupper [lindex $mylist 1]]
if {![file exists "/Volumes/UFS/results/[lindex $mylist 2]/[lindex $mylist 0]"]} {
exec ln /Volumes/UFS/wishlists/[lindex $mylist 0] "/Volumes/UFS/results/[lindex $mylist 2]/[lindex $mylist 0]"
}
}
}
Now, for example, the folder called "Greenpeace" contains every wishlist with that term. Another folder named "Rush Limbaugh" contains the wishlists of all the those interested in reading Rush.
|
On an aside, if you want to delete all the files beginning with the word "search" in a 25,000-file directory, the correct line is:
This line deletes all the files:
Good thing I had backups. There's also a bug, in grep 2.5.1 that corrupts output when grep is run with both the -i and -o flags. Version 2.5.1-1, available through the Fink project, fixes this problem. |
One curiousity revealed by this project is that there are quite a few people who show up for multiple books. Reading On Liberty and Build Your Own Laser, Phaser, Ion Ray Gun and Other Working Space Age Projects? We really should have a special list for you.
Here are the books, along with the numbers of people interested in reading each:
| Book | # of people interested |
| On Liberty |
7
|
| Slaughterhouse-Five |
82
|
| Fahrenheit 451 |
63
|
| Brave New World |
1
|
| 1984 |
76
|
| Critical Thinking |
7
|
| Build Your Own Laser |
2
|
| Apple I Replica Creation |
4
|
| The Catholic Worker Movement |
1
|
| Rebuilding Labor |
2
|
| Michael Moore |
232
|
| Rush Limbaugh |
42
|
| Ralph Nader |
74
|
| Greenpeace |
5
|
| Torah |
42
|
| Quran & Koran |
74
|
| Bible |
3,771
|
The first match for "Bible," ironically, was a wishlist containing The Cannabis Grow Bible: The Definitive Guide to Growing Marijuana for Recreational and Medical Use. Right person. Wrong list. Another match was for The Linux Bible: GNU Testament. With Nader, I foolishly searched for last name alone. Thus, there are quite a few hits for The Lemonader along with the correct results.
If some results look suspiciously low, it's probably because in many cases I searched for a specific ISBN while the book is available in multiple formats. Only the first page of each user's wishlist was downloaded. Books are always added to the front of the wishlist which pushes older titles off the first page, so there is also a slight bias in favor of newer books.
It is possible for users to associate a shipping address with their wishlists, so that others can order them gifts. Though the full address is hidden, city and state remain visible. I already have first and last name. With this information, I can do a Yahoo People Search to obtain an exact street address and phone number. Viewing the wishlists that contained Apple I Replica Creation, I found that all four provided the user's city and state. Of these four, one was a common name that produced multiple hits in his town, two were unlisted (although one of them was in the Intelius database which I opted not to pay for), and the final individual was present on Yahoo People. So I sent him a signed copy and thanked him for his interest.
Thanks to Google Maps (and many similar services) a street address is all we need to get a satellite image of a person's home. Tempted as I was to provide satellite images of the homes of the search subjects, it just seemed a bit extreme even for this article. Instead, I opted only to pinpoint the centers of the towns in which they live. So at least you'll know that there's somebody in your community reading Critical Thinking or some other dangerous text.
City and state were extracted using a regular expression to create a file for each book containing the locations of its readers. Locations were stored one per line, in this format:
Sunnyvale:CA
Salt Lake City:Utah
Reston:Virginia
South Hadley:MA
Nevada City:CA
Walnut Creek:CA
Eagle Nest:NM
Memphis:TN
North Hollywood:CA
Seattle:WA
…
Using the free Ontok Geocoder service, I was able to quickly convert city and state to latitude and longitude coordinates. Ontok uses the public domain TIGER/Line data available from the U.S. Census Bureau to perform its conversion. It took less than an hour to convert all locations from city and state to longitude and latitude:
-122.035011, 37.369011
-111.903656, 40.696415
-77.341591, 38.968300
-72.574860, 42.259102
-121.013496, 39.262192
-122.063980, 37.906521
-105.263031, 36.555302
-90.045448, 35.148762
-118.377838, 34.173100
-122.329430, 47.605701
…
Google has released their Maps API, so a map of these locations can be embedded in this article. The API is simple. Plotting each point requires only three lines of code:
var point = new GPoint(-122.035011, 37.369011);
var marker = new GMarker(point);
map.addOverlay(marker);
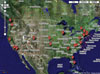
This plots all of the locations on a satellite image of the United States that can be zoomed in to house level. Here are a few interactive samples:
Readers of 1984.
Readers of the Torah.
Temporarily removed due to high volume.You.
The map pinpointing you (your local ISP, actually) requires a good bit of on-the-fly processing, so if the server is exceptionally busy it may not load correctly.
In the future, I may make more sophisticated maps using additional data. Maybe a map that includes all the books in the 260,000 wishlists? Simply searching for any book would present a map of the United States showing the locations of all the people interested in reading it.
All the tools used in this project are standard and free. The services, likewise, are all free. The technical skills required to implement this project are well within the abilities of anybody who has done any programming. The network connection used to download these files was a standard home DSL connection. The computer that processed the data was a 1.5 GHz PowerBook G4. The operating system is Mac OS X 10.4, though everything could have been done just as easily with Linux (and probably with Windows). Not a penny was spent in the writing of this article, just 30 hours of time.
This is what's possible with publicly available information, but imagine if one had access to Amazon's entire database - which still contains every sale dating back to 1999 by the way. Under Section 251 of the Patriot Act, the FBI can require Amazon to turn over its records, without probable cause, for an "authorized investigation . . . to protect against international terrorism or clandestine intelligence activities." Amazon is forbidden to disclose that they have turned over any records, so that you would never know that the government is keeping records of your book purchases. And obviously it is quite simple to crossreference this info with data available in other databases.
On a final note, the FBI is now hiring computer scientists to implement a project that sounds very similar to what I just did:
"Currently, the FBI is strengthening systems engineering in order to tie new systems together architecturally and ensure that standards for custom and packaged applications are enforced, and it needs engineers to accomplish this goal, the agency said.
"The FBI is also focusing on data warehousing as well as federated search technology, which allows a single search query to be deployed across a number of databases, regardless of whether those databases belong to the same protocol or platform.
"'Warehousing has been very successful, yet enterprise extraction, translation and loading processes must be fine-tuned,” the FBI said. “Data engineers are needed to model legacy databases for federated search and participate in legacy transition planning.'"(Computerworld)
This article is the first in a weekly series that will deal with security on the internet and practical steps you can take to protect your privacy. Much thanks goes to Robert Warwick for his help with this project and particularly for writing several of the scripts. Thanks also to Nancy Trump for editing, Michael Fincham for brainstorming, Dr. Bob for bandwidth, and digital.forest for hosting Applefritter. Article submissions are welcome. If you'd like to contact me, please do so via email.
| Attachment | Size |
|---|---|
| 3.89 KB |
{kind=link}
Comments
Wow. I knew this kind of wor
Wow. I knew this kind of work was possible, but I didn't think it over to the detail you have performed. I konw there are many other interest group sites with more direct personal info that can be mined just as easily, bringing a further level of pinpointing "targets" of a probe. This is the kind of article that makes the first story in 2600, and then lands you on the FBI/NSA watch list for sure.
That's pretty interesting.. a
That's pretty interesting.. and amazing.
Kind of slow... oh 2192 guest
Kind of slow... oh 2192 guests? well... blame it on boing boing...
http://www.boingboing.net/2006/01/04/data_mining_101_find.html
Actually, it's the php script
Actually, it's the php script that calculates your longitude and latitude that's slowing things down. Looking at top, the server is still averaging about 86% idle.
Soooo, just search for Arabic-sounding names . . .
and voila! we're rounding up all them there subversive furrin' fellas before yeh knows it. Right? {I'm being facetious of course!}
Damn, the ideas discussed here are scary. Since this info is publicly available, I hate to think what the FBI, et al can access.
As well, it's not at all comforting to know how little oversight the executive branch suffers under these days. Seems us mindless citizens can't wait to hand over more unlimited, secret powers to the police state.
Excellent project and article Tom!
dan k
A step further?
It wouldn't be too hard to take your experiment a step further...
You could grep all of your files into a simple sql db like sqlite or mysql - make a table for user ( amazon id, fname, lastname , city id) , city (city , state ), books ( amazon asin , title, author), then a user_2_books ( user_id , book_id )
Then you could really quickly calculate the odd / 'subversive' combinations of books. Maybe even add in some sort of rating sysetem for books - ie: 1984 or 'on liberty' are worth 10 point each, together they're 100 points, but 1984 and 'slaughterhouse 5' together are worth 0 points because that probably means someone is taking a literature class.
Focus should be on government power
This is an interesting topic, thanks for the article. But the key is the expectation of privacy. As you point out, it's obvious that the information in wishlists are public; you have simply found an efficient way of harvesting it. But it's a far cry from snooping in on phone calls, emails, or what you actually ordered from Amazon or any other bookstore, which *would* have an expectation of privacy, since it is a private transaction between private parties. That's why the library portion of the so-called "PATRIOT" act is so offensive; there *is* an expectation that what you check out of the library is private.
Reason Magazine did an issue about a year and a half ago, in which every subscriber received an issue with their name and a satellite photo of their residence on the cover. The main article was also very interesting:
http://reason.com/june-2004/samples.shtml
http://www.reason.com/0406/fe.dm.database.shtml
At the end of the article, wise words about responding to this situation presented by Mr. Owad's article:
"Databasification, in other words, does have a dark side: increasing government access to private collections of information. Some privacy activists cite this cooperation as a reason to regulate private databases, which makes as much sense as preventing companies from manufacturing binoculars simply because police can use them for unlawful surveillance. The more sensible approach is to restrict the power of the police to snoop in the first place. That means taking steps such as updating the Privacy Act of 1974 to limit government access to outsourced databases; increasing the authority of inspectors general at federal agencies to monitor data abuses; boosting criminal penalties for lawbreaking cops; requiring police to meet higher standards of proof before perusing databases; and, most important, rethinking the drug laws that invite snooping into Americans’ personal lives. (About 78 percent of domestic wiretaps conducted with court oversight in 2002 were for drug offenses. Investigations of violent crimes such as murder, kidnapping, and extortion accounted for just 6 percent.)
Focusing on government power would keep intact the undeniable advantages of databasification -- lower prices, cheaper mortgages, and more-efficient uses of information -- while limiting possible abuses by law enforcement. The aim should be to retain the tremendous benefits of living in a database nation while preventing it from devolving into a police state."
Re: Data Mining 101: Finding Subversives with Amazon Wishlists
Of course, going low-tech ensures that no new info gets out there.
But seriously, there are some really easy ways to minimize your presence on the grid, unfortunately, it is contrary to the conveniences we enjoy. This is why illegal immigrants are often able to live unnoticed for so long in our country; they only need/want the basics to subsist and leave little of a trail behind. It is the average american that clutters up these databases with "noise" that counter-terrorism agencies must sort through in order to see that one "Edgar" out of 260,000+ is the trouble maker because he took a pilot course , bought a book from Amazon on farming and fertilizers and used a debit card at the Starbucks right across from the FBI headquarters all within the last month.
I work in Knowledge Management (metadata) and am honestly not surprised at your results and the speed at which you got them. As alarming as it seems, I do not think anyone should really panic. when dealing with data in such large quantities, you must look at the mean and any deviations from that. This is where those painful statistics classes come back to haunt you. If your reading habits place you thre standard deviations from the mean (or something li9ke that), expect to be watched.
data mining...
I'm extremely impressed with the article, Tom. The amount of fact used is refreshing when reading anything written about security and surveillance. I'm reading this and finding myself saying...
"Good... it's about time they get with the times..."
The U.S. Government is in the business of protecting the U.S. Government. It has been since it's inception some 222 years ago. The idea (advanced by some, not necessarily this article) that all of this "covert" and "secret" surveillance is only happening since 9/11 is laughable.
Presidents and other parts of the U.S. Government have allowed, approved, and even requested warrantless surveillance for at least 30 years, and more than likely much longer.
Now they are using the Internet - along with people's fascination at placing every bit of information they can think of about themselves online - to continue to attempt to protect the U.S. Government.
Good...
I'm on the grid. I can google myself, I can find just about anything about me that I would need to know online within about 20 minutes. I also don't have a damn thing to hide...
I look forward to future installments in this series.
Information Flux in a world of omniscient surveillance
I took an incredible class with Eben Moglen last spring where we covered the privacy, anonymity, and surveillance beat. The fourth amendment is already dead, and not just because identities and activities are being searched, not spaces. The real death of the fourth is wrapped up in the collusion between the private and governmental sector. The info we voluntary sign away in privacy policies, in turn, gets aggregated and warehoused (remember the choicepoint and lexus-nexus scandals last year?) - there isn't even any judicial oversight to the requisitioning of this information.
The real scary part, is that in a post-9/11 world, law enforcement has shifted from investigating crime and gathering evidence, to *preventing* crime. The complete solution to this intelligence operation is, of course, predictive behavior models of every citizen in the country.
Oh yeah. Amazon has built (and patented) part of that module already - patent
I have written an important social analysis and even a proposed solution to help combat this problem here:
http://studyplace.ccnmtl.columbia.edu/Members/jonah/papers/bioport
Peace,
/Jonah
the sad part for you guys ( I
the sad part for you guys ( I am canadian) is that something that Tom whipped up in 30 hours the FBI will spend thousands of hours on and millions of dollars.
You can be sure that there are thousands of semi-competant techies out there hopping on this gravy train as we type.
Clarification
Based on a few responses I've seen, particularly at some blogs linking here, I would like to clarify:
This article in not about Amazon wishlists.
Read Jonah's post.
geek love
The next logical extension is for the lonely geeks out there to start data mining for women with similar interests. I can see it now: DATE mining
as Tom said
as Tom just said, altho he used the Amazon wishlist in his project, it isn't about the wishlist. I took the article as an example of how easy it is to find and manipulate data by someone with no 'in' whatsoever, which implies how easily those with access can track everything you do. Why would anyone think this is actually about using Amazon's wishlist?
Re: as Tom said
Some people think that if they read the RSS headlines, then they've read the news. All they read is a tiny bit, and then they get to assume a whole bunch.
... and assumptions are worth the first three letters of the word...
Purchase Circles
Amazon's Purchase Circles, which list "uniquely popular" books for various locations and organizations, are pretty interesting. Compare books bought by Microsoft employees with those bought by Apple employees.