| Attachment | Size |
|---|---|
| 1.43 MB | |
| 2.01 MB |
{kind=link}
{kind=link}
Hello:
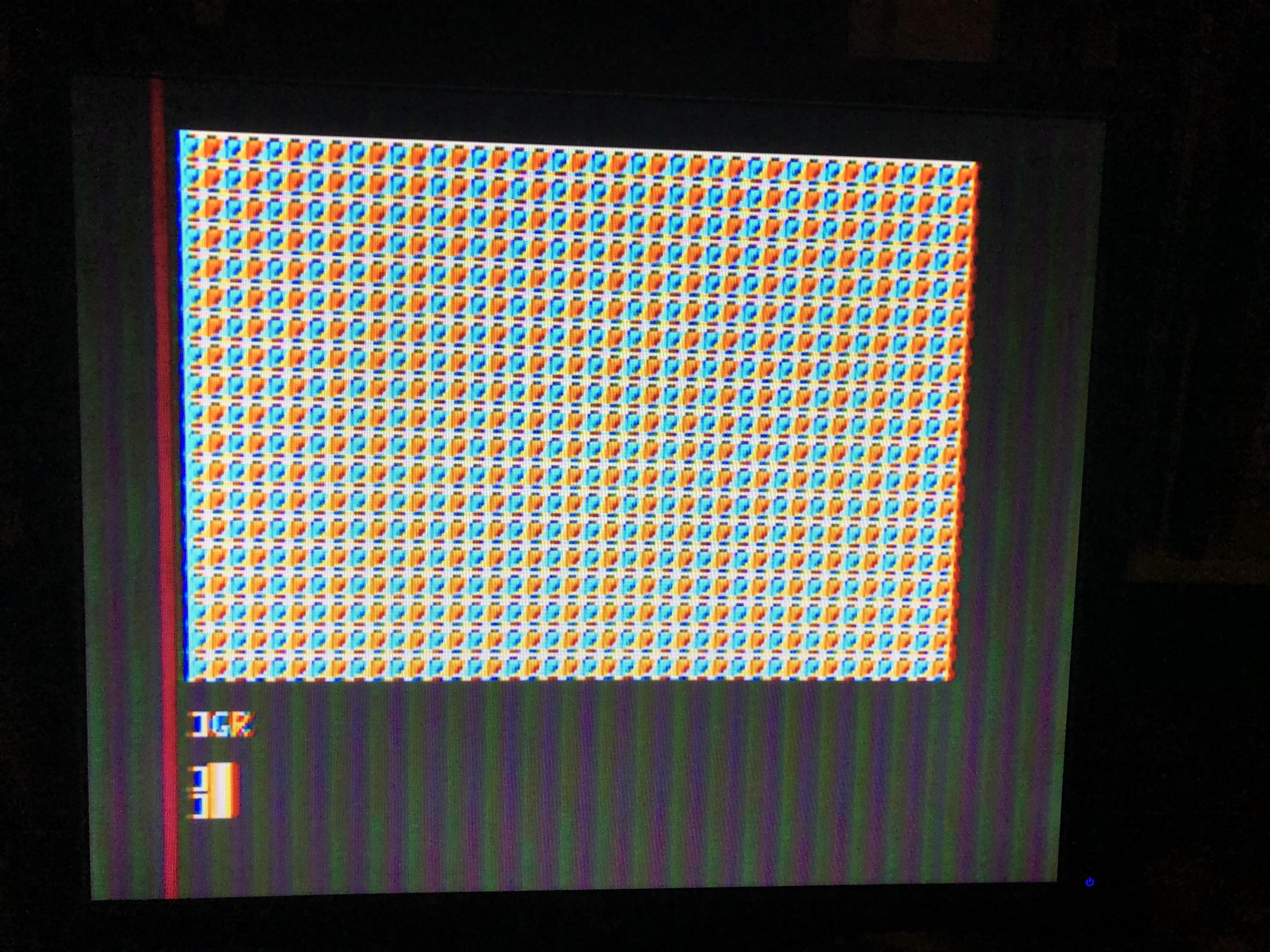
I am new to this site and this is my first post. I recently purchased an early Apple II+ from the estate of its original owner (motherboard date code is 7934). I am trying to sort out a number of issues to get it back up and running.
1) The computer did not boot at first (horizontal lines, no text). After removing all cards and all but the first bank of RAM and removing, cleaning and reseating most of the chips on the motherboard, it now boots up into Applesoft but I see moving vertical bars and text has fringes of orange/blue or green/purple (see photos). I have tried running the video output to an LCD TV and through a composite-HDMI converter to an LCD monitor and I get the same results. Is this normal or is there some adjustment that can be made? Is it possibly a sign of a failing power supply?
2) I have been able to put back all of the memory and reinstalled the 16K language card and the disk II controller and drive. The computer came with a DOS 3.2 master and a bunch of unlabeled diskettes. The drive does not seem to read anything. I tried loading an image from Apple II Disk Server but the drive makes a BLAT sound (that I remember was a bad sign) and I get a disk error. The inside of the Disk II appears to be clean. The head mechanism moves freely and there is no gunk on the head. Is this indicative of a problem with the drive/controller or expired media? The diskettes I have are not labeled so I am not sure if they are DSDD or DSHD. Can the Apple II read/write DSHD disks?
3) On a few occasions, the display has suddenly disappeared and the only way to get the computer back up is to unplug and re-plug the power supply from the motherboard . Is this a sign of power supply issues or something else?
Thanks for your help and happy holidays!
Color fringing on an early ][+ is fairly normal. Some newer LCD will not give a good picture from an Apple ][+'s non-standard NTSC signal. You need to test your Disk ][ with a known good floppy. If you have an early Disk ][ Controller card it may have 13 sector PROMs on it. DOS 3.2 is 13 sector so that is a possibility. 13 sector PROMs will not boot a 16 sector disk, and most are 16 sector. DSHD floppies do not work well on an SSSD system like an Apple ][. DSDD (Double density) is OK, but not High Density.
You should meter your power supply, it should be close to spec levels when loaded. Unloaded readings don't mean much as some power supplies will show close to correct unloaded but will be out of spec under load. A failing supply will sometimes produce poor video, but usually you will get nothing or highly unstable operation. Again, meter it.
That is normal for Apple II to look like that on an LCD- you won't be able to fix it. It is designed to take advantage of 1970's TV technology, so find yourself an old CRT with composite input, or an old monochrome monitor.
As for the booting, it could be a 13-sector card, but that would be odd. Much more common and likely is the cable was plugged in backwards sometime over the last 40 years and it killed the analog card in the drive and /or the Disk ][ card in the computer. I assume you've tried to boot all the disks, and if none of them boot or do anything, likely that is the problem.
If the analog card is blown, most of the time it is the 74LS125 chip. That often acts as a "fuse" for the system. Luckily, that part is readily available and cheap, and since they are normally socketed, easy to replace.
To determine if the controller is 13 sector, one would have to look at the part numbers for the PROMs. Here is the best article I found on how to do that.
https://stason.org/TULARC/pc/apple2/faq/09-017-How-does-one-distinguish-between-a-13-and-16-sector-D.html
As for LCDs on Apple II, it is hit or miss. Some rittwage is absolutely correct -- pretty much nothing you can do will ever get a good picture. Others will work just fine. I have a cheap Emerson branded 19" 720p TV with composite inputs and it works surprisingly well with a ][+ or //e. Graphics look good with reasonable color fidelity and even 80 column text is readable. It actually works as well or better than many period CRT monitors. But I've seen some TVs that were as bad or worse than the picture posted in the original message. Unfortunately, it is kind of trial and error to find one that will work well enough because sometimes even the same model number TV or monitor can have a different motherboard version or firmware revision and it can make a big difference.
Here is some technical info on working on the Disk ][ system.
https://apple2online.com/web_documents/apple_disk_ii_technical_procedures.pdf
http://www.appleii-box.de/H084_5_AppleIIDiskService5.htm
http://apple2.org.za/gswv/a2zine/faqs/Csa2FDRIVE.html
http://www.willegal.net/appleii/apple-service-notes.pdf
Oh and FWIW, most often I've found the MC3470 to be the 2nd most common chip to blow on a Disk ][ Analog Card. So if replacing the 74LS125 doesn't fix it, that would probably be the next one I'd try.
Hello softwarejanitor,just one simple request:If you refer to othe sites, please make sure that reference is correct.In my case at my site the reference to:http://www.appleii-box.de/H084_5_AppleIIDiskService5.htminsn`t correct....The reference to the correct entrypage is:http://www.appleii-box.de/H084_1_AppleIIDiskService1.htmsincerelySpeedyG
What do you mean by "correct"? The link I provided displays the page that I intended.
Thanks for all the input. I have confirmed by part number that I have the 16-sector PROMS.
I have tried pulling, cleaning and reseating the ICs on the disk controller card and on the analog board and nothing has changed.
The local electronics shop is closed today so I will go get my hands on a new 74LS125 tomorrow and hopefully that will fix things. The MC3470 seems to be a bit harder to come by so I hope that it is still good...
Another bad part of that fault with the disk drive board... If this is indeed the problem and you tried to boot every disk, then track 0 will now be erased on all of them. :(
This doesn't always happen. Also, if I remember right it is the Duodisk or Unidisk 5.25 that are more prone to this issue than the Disk ][.
I doubt it, since you can't even plug those disk drive cables in wrong. Well, unless you really, really tried.
But yes, I've had seen the reversed or mis-keyed cable erase every disk put in the drive on Disk II's many times.
There are other ways to blow the 74LS125 that can happen to the Unidisk 5.25 and Duodisk. You can't plug the cable in backwards or off a pin very easily but you can plug or unplug it at the wrong time. I've just heard of numerous cases of Unidisk or Duodisk drives that would erase disks. I've never had it happen with a Disk ][ myself, knock on veneer.
I have replaced the 74LS125 but that has not changed anything :( Does anybody know where I can get an MC3740 or better still a tested working Disk II at a reasonable cost?
Depends on what you consider a "reasonable price". I've been able to pick up a few Disk ][ off eBay over the past few years in the $20-$25 range. There are always a bunch for sale. Tested, not usually because 90+% of the people selling them are completely clueless, but most of the ones I've bought that weren't cheaper than that and known to have some issue have been fine. I've picked up a few parts drives for around $10 each. The shipping was more than the drives themselves by a couple bucks. But buying through eBay or something like that is about the only place you're usually going to reliably find them. There used to be a few sites that sold tested and working drives a few years ago, but they generally were 2-3x more, for their trouble of testing and maintaing inventory, which is only fair. But at those kind of prices you can buy a couple of them and more than likely end up with at least one working drive and some spare parts.
Over the last few weeks, I have been looking on eBay and at some resellers and it seems like working/tested or non-working drives are going at the $50+ range . I am in Canada so I need to add shipping and duties plus roughly 30% currency exchange rate. It is the shipping and currency conversion that really hurt.
Ideally, I'd like to find a tested, working drive from a seller in Canada or the northeast US to minimize shipping costs.
For some good news, I did manage to get my hands on a Commodore 1702 monitor and the display issues have gone away.
Like anything on eBay, you have to be dilligent and patient to find the good deals. I would never pay $50 for a Disk ][ drive, there are just way too many of them out there. Shipping does suck. I just plain won't deal with international shipping except for stuff coming from China, which is cheap enough to put up with how slow it is.
Here is two for $50 BIN OBO out of North Dakota.
https://www.ebay.com/itm/Lot-of-2-Vintage-Apple-Computer-Disk-II-Drive-Model-A2M0003-Apple-II-Computer/173721660112
No response from North Dakota. However, I did receive my FloppyEmu in the mail today. I have been able to run diagnostics on the computer and everything seems to check out. I was even able to run CP/M with the Microsoft Z80 card that came with the machine and that is working fine. I can play around with the machine for now but I still want to get the floppy drive running at some point. I have ordered some of the other chips on the analog board that tend to blow and we will see if that helps.
For now I still have a couple of keys on the keyboard that are not working and I would like to get my hands on an 80 column card -- how much do those go for these days?
[quote=e30_325is]
No response from North Dakota. However, I did receive my FloppyEmu in the mail today. I have been able to run diagnostics on the computer and everything seems to check out. I was even able to run CP/M with the Microsoft Z80 card that came with the machine and that is working fine. I can play around with the machine for now but I still want to get the floppy drive running at some point. I have ordered some of the other chips on the analog board that tend to blow and we will see if that helps.
For now I still have a couple of keys on the keyboard that are not working and I would like to get my hands on an 80 column card -- how much do those go for these days?
[/quote]
I've seen Videx Videoterm clones go for $30-$50 on eBay fairly frequently. The nice thing about a lot of the clones is that many of them have the "soft switch" functionality built in which is nicer than the original Videx cards.
[quote=e30_325is]
No response from North Dakota. However, I did receive my FloppyEmu in the mail today. I have been able to run diagnostics on the computer and everything seems to check out. I was even able to run CP/M with the Microsoft Z80 card that came with the machine and that is working fine. I can play around with the machine for now but I still want to get the floppy drive running at some point. I have ordered some of the other chips on the analog board that tend to blow and we will see if that helps.
For now I still have a couple of keys on the keyboard that are not working and I would like to get my hands on an 80 column card -- how much do those go for these days?
[/quote]
Hi. I am 60. Just found this site. Bought my first Apple II+ back in 1983. I worked as a computer technician on IBMs back then and was friends with someone that worked for an Apple dealer and repaired them. I have some diagnostics stuff. I have the old Franklin computer shop disk with diagnostics that will check memory, check ROM and run a disk drive test. Also have alignment disks. And the Apple diaganostics document for the Disk II. I also have four of the old Franklin disk controllers, which are much easier to keep alive since they can be modified to accept a 2716 Eprom. I also have the ROM code for the card. Another board I built back then was the DOSS HOSS from the Jim Sather book Understanding the Apple IIe. Modified the integer basic card to accept 2732 eproms and moved the DOS to the card so it would boot instantly on power up. Worked sweet. I still have that card around.
I just pulled my Apple II+ our of the closet recently and got it running. Had to repair the main board and also one of the DISK II. On the disk II I had to replace the CA3146E chip. Mine was not reading.
I have a few Apple II+. One I modified the main board long ago to accept 2716 EPROMS so I could keep it alive not having to deal with those 9316 PROMS.
For a fresh version of DOS 3.3 find that Geekpub site. This guy has tons of Apple II software that you can download via the cassette port and it will automatically format your disk and copy over the software from his web server. Pretty slick. Google Geekpub Apple II.
Of course you need a working Disk drive to download and make the disks. But if your software is questionable, it might be worth going to the site and trying to create a DOS disk.
I would love to see a photo of that DOSS HOSS card you built.
This works in a IIe fine. I need to change something in my II+ to make it work. There is a conflict with the 16K memory card. The Jim Sather Quickloader is the commercial version of this. He went through making the DOSS HOSS in understanding the Apple IIe. Then he went on to create the Quickloader.
You can go to the link I pasted below for the original doc on the Quickloader. It has info on changes to make to a II+ so it will work. I am thinking I need to make those changes so my DOSS HOSS works. Or, it is not working because it has been sitting around for 25+ years and has a problem. It makes the beep sound, but DOS doesn't load. I can do the reset key sequence and get into the monitor, so it is partially working. I am in the process of trying to figure out what is wrong.
https://www.apple.asimov.net/documentation/hardware/io/S.C.R.G.%20Quikloader%20-%20Read%20Me%20First%20-%20Installation%20Manual%20%28V4.2%29.pdf
DOSS_HOSS_1.jpg
DOSS_HOSS_2.jpg
I have some old Franklin stuff too. Several disk controllers and some bare board 16K memory cards. I was heavily into Apple in the 80's. Collected various things. EPROM programmer. Sold a bunch of stuff over the years, but still have several of my old books, like the circuit diagram book and Repairing the Apple II+ and IIe book. Interfacing and Digital Experiments book. I was doing robotics back then and did a lot of interfacing to my Apple II+.
FranklinDisk_1.jpg
Board modified so I could swap out the 2708 for a 2716.
FranklinDisk_2.jpg
I appreciate you taking the time to post the photos. The HOSS card is something I would like to see more detail of if we can arrange it.
A few folks here are aware that I've spent a considerable amount of time with the QuikLoader. I loved working with that board 35+ years ago. Here I am back at it...
I recently reverse-engineered the board and put a 512K x 8 flash EEProm in place of the 8 UV EPROMS.
Flashing the 512K x 8 EEPROM is 20 seconds away from done, where burning 8 EPROMS can challenge your patience. (nearly an hour to finish)
If you look at some recent posts, you will see that AppleFritter member DavidM has taken it even further by reducing the TTL logic down to (nearly) a single chip. Nice work on that project. David has a small collection of "Reboot" projects that are really quite interesting.
He published his board as the "QuikLoader Reboot". While he was making the board, I prototyped up a full TTL version of the same thing and called it "QuikLoader Compact". Both boards essentially do the same thing. Our AppleFritter member MI2K made up a PCB based on my TTL prototype, which will be posted here soon. I'm in process of making up a couple of useful Flash ROMS for the board now. One will be a Games ROM, the other will be a Utilities ROM. You'll have a choice of selecting DOS or ProDOS (or nothing) at boot and the card will present a nice Program menu like the QuikLoader did back in the day. You won't be disappointed when they are complete and ready.
I would love to reverse engineer your HOSS Card if you're ever willing to let that happen. I do professional quality PCB work in my spare time. :)
QuikLoader Compact: <- Click to view, hand-wired prototype below
QloaderCompactProtoSm.jpg
Looking closer at your DOS HOSS board ... It looks like a standard Language card containing D0 thru F8 ROMS.
I see nothing there that would resemble a QuikLoader card. (?)
It is the Apple ROM card that contained Integer basic ROMS with a switch so you could flip it and boot Integer basic instead of Applesoft, not the language card. I followed Jim Sather's instructions to modify the card so it accepts 2732 EPROMS. You then move DOS so you can save it to disk. You build up binary code so that you have a boot ROM and DOS on the card. I programmed each 2732 EPROM as set forth by Jim Sather. I had to key in all his assembly code from the book, move DOS around in the Apple so I could save it to file and then I burned each eprom. I labeled them the same scheme as the ROM chips so I knew which socket each EPROM went in. With the switch on the card positioned so that it would normally select to load Integer basic, instead the card contains code that loads DOS. There are also some reset routines on the card that can throw you into the monitor.
Read through "Understanding the Apple IIe" by James Sather. In the chapter where he discusses ROM is where I think he goes over building the DOSS HOSS. The card is designed to just load DOS quick. Later James Sather took his idea farther and designed the Quickloader. I built this thing in the late 80's, so it is a little fuzzy all I did with the code, but I know I followed this instructions from his book.
So with the DOSS HOSS, the switch changes to boot DOS from card or ignore card and boot from disk.
JAFO, thanks for that explanation. I couldn't see that you had 2732's in there but I can certainly see the attached jumpers.
I have Jim Sather's book, and now that you have me curious, I'm going to check it out.
Thanks for sharing!
That is the neatest laid out perfboard I've ever seen. O_O
Hi everyone, I'm having the same problem with my disk drive. Spins forever and doesn't read. I'd appreciate any other suggestions you have.
I've cleaned the head and even tried replacing the 74LS125 chip. Has anyone had success replacing MC3470 or CA3146E on the drive's analog board?
I moved and all my books and papers are boxed. In one of the boxes I have Troubleshooting stuff on the drives. If you flip the drive over, are the timing marks showing the correct speed of the motor. as I remember the large wheel has timing marks. there is a pot to adjust the speed on the motor control board. The MC3470 is a read amplifier and reads the data from the magnetic head. I will look for my notes and post if I can find them.
This site link will be helpful. Sam's book on the Disk II- https://www.google.com/url?sa=t&source=web&rct=j&url=https://mirrors.apple2.org.za/Apple%2520II%2520Documentation%2520Project/Books/Sams%2520ComputerFacts%2520-%2520Disk%2520Drive%2520Apple%2520II.pdf&ved=2ahUKEwj1xZrUpersAhUIoXIEHXhcDloQFjAAegQIAhAB&usg=AOvVaw2mCJy6IqEQLUXe6tsAXbaR
Remember to use an incandescent light bulb to evaluate the speed of the wheel - you don't want anything that may pulse the light!
Thank you Tony359 and JAFO! I'll read that over this weekend and try it out. The only thing I can see that can be adjusted is the screw on VR1. I'll try to dial that in.
IMG_20201104_231132720.jpg
So I had a strobe light and tried making the pattern stand still at 50hz and 60hz. Still no dice. I'll keep trying but so far it doesn't appear to be the speed.
As a first test, I would check if the controller is seeing any signal at all. You can test this easily by entering the monitor, making the drive spin (read $C0E9 to turn the motor on, $C0E8 to turn it off) and then read the value of the controller's data latch ($C0ED). The latch should show constantly changing values while the disk is spinning (with a disk in the drive, of course). When the data isn't changing, then it's certainly not the speed. And the latch needs to show constant data when the drive isn't spinning.
I had an issue with a broken P6 PROM a while ago, so the data latch was dead - even when the drive was spinning. Probing with an oscilloscope I could see a digital signal on the data line from the drive to the controller though. That confirmed there was an issue on the controller board (on the Apple II side, not in the drive).
Hi MacFly, I entered the monitor and tried those commands but I didn't get the result you described. Perhaps I'm not doing this correctly. Here is what I've tried.
]CALL -151 <RET>
*$C0E9 <RET>
*$C0E8 <RET>
*C0ED <RET>
The second command doesn't start the motor and the last two commands also do nothing. I'm not familiar with monitor commands yet but I'm learning.
The "$" was the usual way of writing a hex number in those days - but the monitor does not accept it. All data in the monitor is hex anyway.
The addresses assume the disk II card is in slot #6. Data to be read is in C0EC though (not C0ED as I wrote above), so:
Enter the monitor:
CALL -151
Turn on drive 1 (all addresses for slot #6):
C0E9
Enter read mode (it should be in read anyway):
C0EE
Read data:
C0EC
C0EC
C0EC
...
Turn off drive:
C0E8
Have you tried the Disk ][ card in slot 7 by chance?
Here are the results from the monitor commands. Note: <RET> is me hitting return to enter commands and the characters below are the response from the monitor.
C0E9 <RET>
C0E9- AE
C0EE <RET>
C0EE- 04
C0EC <RET>
C0EC- 80
C0EC <RET>
C0EC- 08
C0EC <RET>
C0EC- 80
C0EC <RET>
C0EC- 82
C0E8 <RET>
C0E8- 0A
Yes, I've tried it in both slot 6 and 7 in two machines (the one I'm using now has a working DuoDisk and functions perfectly.)
So in order to load diagnostics and test the drive using software I've added my working DuoDisk card in slot #7 and the Disk II Interface card, connected to the non-functioning disk drive into slot #6. On boot I'm able to load a copy of Master Diagnostics IIe and I ran the Drive Read/Write Alignment Test on the non-functioning drive, which tells me it's unable to write to disk.
Something I already knew but at least I've checked that box. Is there better software out there I could try?
Thankyou for your help so far, I'll figure this out some day.