Apple /// Reset Logic & Apple II Emulation Flaws
I recently ported software from the Apple II to Apple III and encountered an interesting topic. It's a corner case, but in my opinion a typical example. It shows how the Apple III design was sometimes (maybe unnecessarily) complicated. And how features introduced Apple II compatibility issues.
Background
I had implemented a firmware update utility for the DAN][ Controller card on the Apple II. This utility uses Apple II's "warm start handler" feature. It's an option to execute a custom handler whenever the user presses RESET.
I needed this feature for my firmware update utility as a method of triggering a hardware reset of the interface card. This would cause the card's microcontroller to reset and execute its bootloader. And I needed the warm start handler in order for the 6502 to then very quickly talk to the microcontroller, before a timeout expired and it left its bootloader to launch the normal application from flash memory.
Using RESET & bootloader for firmware updates is actually a very common approach - since it provides a failsafe update mechanism. It even keeps working when a microcontroller's normal application in flash was "bricked".
My utility was working great on the Apple II. So, I was looking on properly porting it for the Apple III...
Warm start RESET on the Apple II

Here's what happens on an Apple II when a warm start RESET is triggered:
- The user presses RESET.
- A full system reset is triggered. This affects the entire mainboard, all I/O slots (and interface cards) and the 6502 CPU itself.
- Once the RESET button is released, all I/O resumes operation - and with the following clock cycle, the 6502 fetches the address from its RESET vector ($FFFC/$FFFD) and starts executing.
- The Apple II executes the ROM's RESET routine. It quickly determines whether a warm start or normal system reset was requested (Apple-CTRL-RESET), and if a warm start handler was previously registered by software.
- Eventually the ROM calls the registered warm start handler - just a few microseconds after RESET was released.
Easy. A simple feature really. Works great on the Apple II...
Apple /// warm start vs NMI

So, I was considering how to implement the same for the Apple III. But, oh dear! The Apple III has no such feature. The Apple III ROM was hardcoded to always boot from floppy. It doesn't care to distinguish between warm start and normal system RESETs.
It does have an option, however, to trigger an NMI interrupt when the RESET button was pressed individually (rather than Control-RESET). But that's not the same. And it doesn't help with my application. It does not trigger an I/O hardware reset, like on the Apple II.
So, too bad? Nothing we can do? Well, wait, there's more...
The Apple III has an "Apple II Emulation Mode". And to be Apple II compatible this does support a warm start RESET routine.
Well yes, but...
Apple /// Reset & Apple II Emulation Mode
The Apple III supports a warm start RESET, when Apple II Emulation Mode is enabled. It has special mainboard logic to support this, which changes the board's normal RESET behavior. And this feature is probably a little more complicated than you may think it is...
Here's the relevant schematic:
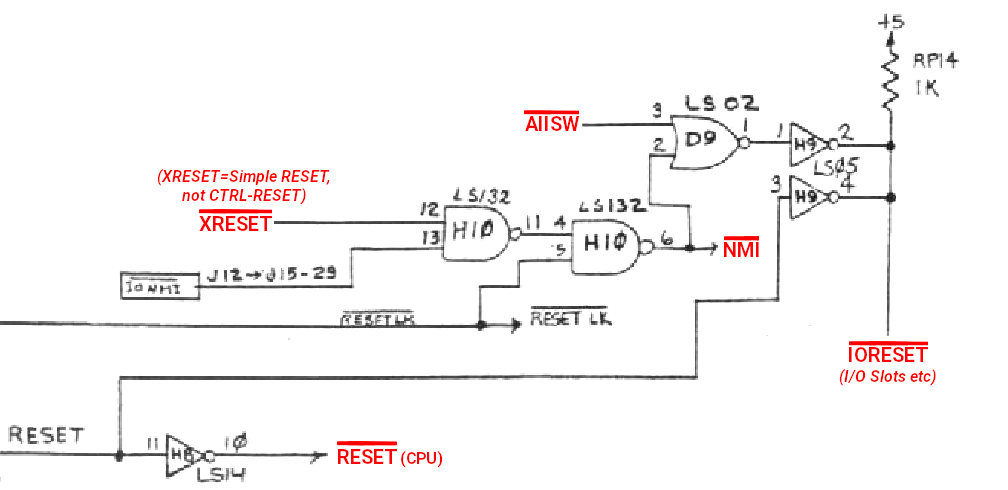
(And remember, all this logic is implemented with basic SN74xx LS TTL ICs on the Apple III...)
- "/RESET" is the normal "CTRL-RESET", which triggers a full system reset. This, however, also ends the Apple II Emulation Mode and boots the Apple III back in native Apple III Mode.
- "/XRESET" triggers when the "RESET" button is pressed individually. It triggers the NMI interrupt on the Apple III. However, if Apple II Emulation Mode is enabled (/AIISW=low), then it also triggers an IORESET.
- There is also a feature to lock and prevent a RESET (/RESET LK), but we ignore this here.
So, when the Apple III is configured for Apple II Emulation, it is splitting the mainboard's RESET signal into two separated domains. The RESET button triggers an I/O reset - which only affects the I/O slots and some related logic. But it does not trigger a CPU RESET. Instead, it also triggers an NMI interrupt.
Patched ROM
In order for the Apple II Emulation to behave like a real Apple II, the Apple III used a slightly modified copy of the Apple II ROM for emulation. Apple patched the NMI vector ($FFFA/$FFFB) to point to the same address like the 6502's RESET vector.
So, when the user presses the RESET button in "Apple II Emulation Mode" then:
- All I/O slots receive a hardware RESET.
- The 6502 does not receive a RESET, however, it triggers the NMI interrupt, which triggers the same routine like the Apple II CPU RESET.
So, all is good, right? The Apple III is fully able to mimic the Apple II behavior. Software couldn't tell the difference?
Well, no. It's a complex & clever approach. However, it is flawed...
What's wrong with Apple III's "warm start" when emulating the Apple II?
While the idea of using the NMI interrupt to mimic the Apple II warm start behavior on the Apple III was clever, it has a significant flaw. It's a matter of timing:
- NMI is an "edge triggered interrupt". And it triggers on the falling edge of the input signal. And as shown by the Apple III schematics, it triggers at the very moment the RESET button is pressed (when the "/XRESET" signal goes LOW).
- The RESET and IORESET signals, however, are "level-triggered" signals. As long as IORESET is low, all I/O is reset.
What could possibly go wrong?
The problem on the Apple III is that:
- Pressing RESET immediately triggers the NMI. This causes the 6502 to execute the warm start routines with the next clock cycle. Within a microseconds...
- However, no matter how quick you are in releasing the RESET button, IORESET is asserted much longer. At least several milliseconds - due to the debouncing logic. But a normal user would probably keep the RESET button pressed for a few hundred milliseconds or maybe an entire second anyway. Meanwhile the 6502 CPU is already executing code...
This behavior is clearly different on an Apple II. On the Apple II the CPU and I/O are both blocked while RESET is pressed. And both, CPU+I/O, will resume normal operation with perfect synchronicity once it is released.
Reproducing the Issue
Here's a simple example reproducing the issue on the Apple III:
- Load the Apple II Emulation disk.
- Enter Apple II Emulation Mode (press RETURN).
- Go to the BASIC prompt (briefly press the RESET button individually).
Now:
- Press the RESET button again, but this time keep it pressed.
- With the other hand, type
PR#6 (RETURN)
- Now release the RESET button.

The disk drive does not start spinning. The machine is stuck (frozen). The routine accessing the disk drive isn't prepared for the drive and controller card to be unresponsive (since RESET was still active when you typed "PR#6").
The same would have affected any Apple II software, which used the warm start routine and tried to immediately access any I/O following a warm start. This was never an issue on Apple II, since this machine never starts executing code while RESET was still asserted. But such software would have issues in Apple III's "Apple II Emulation Mode".
Workarounds?
Workarounds are possible. I added a little Apple III-specific routine to my firmware update utility. It checks and waits until IORESET is released, detecting when the user has finally let go of the RESET button. It does so by accessing the I/O device on the DAN][ Controller card, and checking if the device is already able to respond. Read/write I/O operations are ignored until IORESET was released.
Moral of the story?
Well, it just demonstrates another imperfection in Apple III's "Apple II Emulation Mode". When simple things (like a CPU hardware reset) are implemented in a rather complicated manner, subtle issues are easily introduced...
Did it affect any actual Apple II software back in the day? Hard to tell. There is a good chance that it didn't. Most of the serious, more complex Apple II business software wouldn't run on the Apple III anyway. Other, more fundamental limitations were already preventing the software from starting in the first place, like the hardware limitation of only allowing 48KB of RAM in "Apple II Emulation Mode"...
- MacFly's blog
- Log in or register to post comments
Comments
The problems with the Apple /
The problems with the Apple ///'s Apple ][+ emulation was part of the reason for the (relative) failure of the Apple /// platform. Apple did a lot of things on the /// that as you say were unnecessarily complex. And in the case of the emulation, they went to a lot of work to limit it to a stock 48K Apple ][+. The emulation can't access a ton of features. Apple did this on purpose, because they thought by limiting Apple ][ compatibility to the minimum it would encourage development of more Apple /// specific software since the /// had a lot of cool features which required add-ons for the Apple ][ to do. Like lower case. Like 80 columns. Like memory above 48k (this was before the //e which came with 64k). Apple could have made the /// be able to emulate a much more capable ][. Titan's ///+][ card fixed a lot of these things but when you look at what they had to do to work around things Apple did it is kind of sad. Later Titan had the ///+//e, which was even better. I personally think if they /// had come out of the box with these capabilities it probably wouldn't have caused much less /// specific software to be built, and it would have made the /// much more popular since it would have been able to tap into a much bigger chunk of the massive Apple ][ software library. So basically I completely agree with you.
Interesting to note that Joe's Computer Museum is res-issuing the Titan ///+//e now. This, plus their /// Softcard clone (Z80 for CP/M) and a Dan ][ emulating a Profile... Pretty much makes the ultimate Apple /// system. Even better to swap out the floppy drive with a FloppyEmu with the right cabling set-up.
Interesting finds ... may help to understand the Apple IIe MMU
Hi MacFly -
this is an intersting find of yours. It shows that Apple III designers were struggling with getting the RESET right and still allow warm- and coldstarts.
I don't have an Apple III, but this blog entry of yours nudged me to revisit the weird way they reset the MMU on the Apple IIe. As we have known for a while, the MMU has no RESET pin but instead uses an internal state machine which looks for the RESET cycles initiated by the 6502 in response to the release of its physical RESET. Which appears to be treated in the same way as an IRQ except that it will wait until the RESET input is deasserted. It then pushes the processor status and the return address on the stack (3 x stack area writes) and then fetches the RESET vector from $FFFC+$FFFD. Much the same as what happens with any other interrupt on the 6502, except for minor details like the sensitivity of the input and the address of the vector itself.
The state machine in the MMU looks for exactly this sequence: 3 x write to stack page, and 1 x read from $FFFD, and during that read, resets all its internal soft switches. Which control the memory configuration.
So far everyone (including me) simply believed that this complication was added to the MMU because they had no pin left over for a RESET. But now, with your discovery on the Apple III and your line of thoughts, I think it was necessary to do it this way (with the state machine) to avoid screwing up the execution of the last instruction after the RESET pin is asserted. The trap here is that if it's a write cycle into banked memory, and the banking configuration would get RESET instantly, during that write cycle, that data byte might get written into the wrong place, and this could corrupt code or data which was residing in another bank. If you ever want to allow for warmstart-ish action after a RESET, and hence rely on the integrity of the memory contents, you simply can't allow the memory configuration to get switched during that last write cycle before the 6502 RE SET sequence takes over.
Hope everybody reading this can understand my line of thoughts. And why they - very likely - had no other option for the MMU than to make it reset its internal soft switches just at the right point in time, which appears to only be possible to accomplish with said state machine looking for the RESET sequence.
So here you have a case that shows how having bank switched memory can open a whole can of worms, if any warmstart feature is wanted after a RESET. The question if the solution in the Apple IIe is failsafe under any conditions stays open. The Apple IIe seems to work fine, but is it possible to design a set of circumstances where the system loaded into memory may get corrupted despite of the elaborate MMU state machine ? Hmmmm.
At lest we now know that all this is not as trivial as it seems on the surface.
- Uncle Bernie
I think you're probably right
I think you're probably right about the way reset cycles are handled in the //e MMU. I suspect that the designers of the //e ASICs were familiear with the Apple /// design either because they worked on it or studied it a lot. Athough the /// is often maligned as a terrible design, it was at the time it came out one of the most ambitious and complex (arguably in some ways overly and unecessarily completx sometimes) desktop computers when it was designed in 1979-1980. When you look at how much they crammed in there as far as features go compared to just about anything else on the market at that time it's amazing it worked at all. And the //e obviously in a lot of ways I think was the result of things Apple learned with the ///. It was obviously simpler and less complex, but it actually had a pretty good amount of the capabilities, albeit needing several cards to do what the /// did all on two boards.
I'm not buying this
I'm not buying this explanation.
When the RESET line is brought low, reading and writing to/from the CPU is inhibited. But even if the situation was as you described, it would only take a delay of one clock cycle to allow the write to complete before resetting all of the softswitches. This would be much simpler to implement than the stack/reset vector fetch via the state machine. So I believe it probably WAS just for lack of another I/O pin that this was done.
Think again, Jeff ...
... you wrote: " When the RESET line is brought low, reading and writing to/from the CPU is inhibited".
This is not an exact description so your rejection of my theory seems to be premature. This is how I see it:
The 6502 samples its RESET input during PHI2 but does not react to it until the next PHI1, where its internal, active high, RESP signal is asserted, and this is the signal within the 6502 which affects (all too many for hand analysis) gates within its control logic. So if the RESET input gets asserted during a write cycle, it will not block the write. The write will happen. So the MMU can't change its memory configuration switches during that write cycle, to avoid writing into the wrong memory bank, if another memory configuration other than the RESET state was selected.
The MMU itself does not gate all memory enable signals it generates with RESET, and even if it does, it uses the internal RESET signal which is generated by the state machine during the read of the $FFFC address, fetching the low address byte of the RESET vector. This must come out of the ROM so the memory select soft switches must be reset just at that point in time, not sooner, and not later, to make it access the ROM. The story with the IRQ and NMI vectors is different, as Apple's system software sets up copies of these vectors in all relevant RAM banks, so the vectors - hopefully - are there when needed, regardless of the memory configuration at the time of the IRQ or NMI interrupt vector fetch. The fact that the zero page and stack pages can also be in either the MAIN or the AUX memory complicates matters but Apple took care of that by proving their own interrupt service routines and warning the user about writing their own, stating "it's complex".
See how many worms crawl out of that can ? I'd rather have a different type of bank selected memory, where zero page and stack and the interrupt service routines stay in place. But the 16k language card set the course they had to take to stay compatible.
As a general footnote / concern, I think it is extremely stupid to use an asynchronous RESET signal anywhere in a system. You simply can't gate things in your memory enable logic (or elsewhere) with a signal coming from a bouncy keyswitch. This invites disaster, unless the system is swiped clean and restarted from scratch after such a crude RESET. The proper way to do it on a circuit level is to a) properly debounce the key and b) then synchronize the debounced signal with a system clock in such a way that the synchronized RESET signal going into the system never changes at inopportune times.
The 6502 uses an internal synchronizer flipflop on its RESET input for a reason. Alas, it is not 100% failsafe against synchronizer failure / metastability, but it's good enough for the 6502 having been a tremendous success.
I was pondering over replacing the state machine with something simpler (as it steals too many macrocells in my PLD implementation of the MMU, under development) but so far I have found no good solution. One idea was to use the SYNC signal from the CPU to synchronize the RESET in such a way that it always allows a running instruction to complete, but this idea was quickly abandoned when recognizing that the 6502 could 'hang' without generating any more SYNCs. Maybe the idea can be salvaged , but then again it would consume even more macrocells than the original state machine, and it is irrelevant for a drop-in MMU replacement anyways, which must use the original state machine.
The whole topic of using RESET and then allowing a warm start is tricky. It boils down to what happens exactly at the point the RESET takes effect. Will it corrupt something ? The original Ohio Scientific Superboard II computer infamously had that deceiving D/C/W/M prompt after each RESET invocation, and yes, you could choose "W" to warm start a machine just after it was turned on, and see it crash. The Atari 400/800 did not allow the user to push a RESET button at all - the "SYSTEM RESET" key goes to the NMI, and the internal RESET as such only happens at power up. This is why the Atari 400/800 can't be revived with the "SYSTEM RESET" key after it executed one of the "HANG" instructions (opcode $02 and others). You had to power cycle it. Of course, people tried a mod to give it a real RESET key (the so-called "hard reset" mod) but then they complain it doesn't work in some cases. Atari 600XL/800XL connected the "SYSTEM RESET" key to the real RESET signal and the firmware attempted to detect if it was a cold or warm start by looking at one (one !) RAM location, and this failed badly and led to a warranty return deluge after Japanese DRAMs got so good (excellent wafer quality) that this RAM location could "remember" its contents for minutes after the power had been turned off. When turned on again, the RAM contents was mostly corrupted, but if that one location still had memorized the right value, then the firmware would falsely assume warm start and crash. The onlt remedy was to wait for maybe 5 minutes before urnign the machine on again, and the typical user would bring the poor Atari 600XL/800XL back to the dealer for a refund / warranty exchange. Maybe this contributed to the demise of the Atari 8-bit line.
I'm mentioning these other computers here on an Apple website only to show you what could go wrong (and did go wrong, badly) with RESET in a warm start context. Hope this keeps you from falling into the same trap. After 35 years, lots of knowledge gets forgotten, and people repeat the mistakes of the past again. This is why "oldtimers" like me should tell these snippets of anecdotal wisdom before it dies with us.
- Uncle Bernie
Definitely getting into the
Definitely getting into the weeds here, but:
1. My comment that you quoted comes directly from the Synertek data sheet.
Synertek reset.png
2. You wrote "... the memory select soft switches must be reset just at that point in time, not sooner, and not later, to make it access the ROM."
There seems to be no reason why the the switches could not be set earlier. The fake reads of the stack before fetching the Reset vector are ignored by the CPU. So again, even if we were worried about a write cycle in progress we can safely reset the memory switches after that cycle completes; no need to wait until just as the vector is being fetched. Of course, Reset is also a "destructive" process. Whatever program that was running when it is asserted is immediately halted. So one can make few assumptions about what is in memory after that anyway.
Just my $0.02
Hi Jeff -The Synertek
Hi Jeff -
The Synertek datasheet for the 6502 (a copy from the MOS Technology datasheet, but typeset, so looking nicer) does not really tell the truth about how the 6502 RESET works internally to the 6502. You need the original transistor level schematic of the 6502 to really see the fine details. The openly available ones based on reverse engineering do not have the names on the internal signals.
You wrote in your preceding comment:
- "There seems to be no reason why the the switches could not be set earlier."
Yes, there is. If the RESET is wired to the MMU directly, and flips the memory configuration soft switches just before PHI2 of a write cycle, this write cycle could end up corrupting the wrong physical memory location.
- "The fake reads of the stack before fetching the Reset vector are ignored by the CPU."
Wrong. As I wrote above, these are write cycles to the stack, not "fake reads", and they the very same type of information there (processor status and return address) as the IRQ and NMI interrupts do.
- "Of course, Reset is also a 'destructive' process. Whatever program that was running when it is asserted is immediately halted."
No, it isn't necessarily destructive, and the program that was running isn't halted (at least from the point of view of the 6502). It is just continued with a RESET service routine, but of course, after the RESET was deasserted. But I grant you to see this as a "HALT" als long as the RESET is asserted.
- "So one can make few assumptions about what is in memory after that anyway."
Only applies if the system level RESET implementation is botched / too naive. As a system designer, you can only get away with that if it is guaranteed that after each and every RESET, the complete system is cleaned up and rebooted. A rule which some commercial microcomputers violated.
A properly implemented RESET does not need to corrupt memory. If it can be done right for the 6502 is an open question, as I didn't implement it yet, but I have been working on this topic for a while. My main motivation is not Apple specific, but to make the 6502 robust against the "HANG" opcodes, where it ceases to fetch instructions, and consequently, the SYNC output indicating an opcode fetch cycle is never getting asserted again.
Since internally of the 6502, SYNC also triggers the IRQ and NMI sequences, all interrupts are dead if the 6502 "hangs". Only RESET can get it out of there, and this is because RESET, among other actions, initializes the T-state machine in the instruction sequencer, which hangs in an endless loop after any such "HANG" opcode and never goes fetching the next opcode. They should have disclosed these opcodes as "HLT" (Hehehe). Here you have your "HALT" of the user program by means of an instruction. Which indeed did exist in some microprocessors and earlier computers. So maybe the "HANG" opcodes of the 6502 were not an oversight, but were put in intentionally. The designers of the 6502 were experienced, and I'd bet they had built a simulation of their instruction sequencer. Otherwise I see no chance how they could have gotten it right in first silicon, it's not a trivial design anyone could check with pencil and paper in an useful amount of time. And if they had such a simulation they certainly would check all the 256 possible opcodes what they do. So, IMHO, they very likely knew about the "HANG" opcodes and their effects, but somebody decided to not sell it as a "HLT" instruction feature. A similar decision was done with the ROR instruction, it was not forgotten, but deliberately and intentionally taken out of instruction set, the circuit, and the mask layout. This is why the empty spaces in the layout later were available to put the ROR back in.
I don't see this dicusston to be "getting in the weeds". If anyone wants to implement a safe and robust system RESET, all these fine details must be observed, and I just wanted to help with providing some insights into the finer details of how the 6502 works, which are not described in the datasheets.
- Uncle Bernie
Don't want to enter an
Don't want to enter an infinite loop here, so let me just respond to one of your statements:
You wrote: "... these are write cycles to the stack, not "fake reads"
I'm not 100% positive, but everything I've ever read about the 6502 Reset operation says that the stack writes impemented by IRQ, NMI, and BRK are indeed turned into reads during Reset. For example, from the Visual6502 page:
RESET also runs through the same sequence, but it is the most different of the four cases, since it does not write the current PC and status onto the stack – but this was hacked trivially: The bus cycles exist, but the read/write line is not set to “write”, but “read” instead.
So as to the reason why the MMU implements a state-machine for reset, I still maintain that it was a lack of pins. Had the true reset line been fed into the MMU, your edge case could have been resolved with a simple one-clock delay before clearing all the switches.
The 'phantom reads' during RESET are real !
Hi Jeff -
Your above claim that the RESET does three phantom reads on the stack instead of the push/write of the processor status and the return address is correct, and I stand corrected.
I had remembered that differently but wrongly, and age certainly does not help. Has been a long time (maybe 30 years ?) since I had a logic analyzer hooked to a 6502 system. I spent this afternoon inspecting the 6502 schematic because I smelled a rat, and indeed, the RESP signal sets a RS flipflop which blocks the three input NOR that controls the internal !R/W line to the R/!W pad driver. As far as I can see from the schematic, the rest of the NMI/IRQ machinery still goes through the motions to push processor status and return address on the stack, and makes the data internally available, but never drives it on the data bus, as the writes have been turned into reads.
This is why my MMU implementation does not work - its state machine looked for three stack writes which never came. In the simulations it was writes,because that is how I (wrongly) programmed the verification code. So this discussions helped to weed out yet another bug in my MMU. It's still a lot of work to do.
Thanks for that hint, Jeff !
- Uncle Bernie
Whew! Glad we could agree on
Whew! Glad we could agree on something. And that it has helped you with your MMU project.
So do we still think the state machine reset circuit in the MMU was for anything other than a lack of pins?
Reset State Machine in Apple IIe MMU . . .
... has at least the ability to prevent write cycles to end up in the wrong memory bank. But whether this is necessary to keep the Apple IIe safe from this event is an open question I can't answer without deeper simulations of the whole system (6502 + MMU), which at the current state of my work is not functional yet.
As for the 'missing' pin, I ran into the same problem, no pin left for the RESET signal on my MMU implementation (on the EP910 PLD I use) so I pondered over alternate solutions how to funnel that signal into the MMU from the outside. There are some ways to do this, but en route to such an alternate solution I saw that this state machine may have deeper reasons to exist in the original MMU design, so I came up with the theory it also may protect the RAM contents from stray writes, and therefore I did not dare to replace it.
That the RESET topic came up in this blog thread is a sheer coincidence, and I could not resist to comment. Undeniable fact is, there exist many completely botched / risky / wonky RESET schemes in commercial 6502 based computers, some, like the Atari 600XL/800XL involving bank selected memory, buit not exactly the same as in the Apple IIe (or earlier ones with the 16k language card), so why not write down what I know - or seem to know - about the topic.
- Uncle Bernie